





Why Data Annotation Is the Most Underrated Investment in Business Banking AI

Raw data creates visibility. Annotated data creates intelligence. Most institutions have the first. Very few have built the second.
Raw data alone does not create intelligence in business banking. It is annotated data that does. This article explores why data annotation is the most overlooked yet decisive investment in the AI stack and how institutions that build proprietary, annotated datasets are constructing the only competitive advantage that cannot be replicated.
In the previous article we argued that the future of AI in business banking will not be determined by models alone, but by how effectively institutions capture and operationalise unstructured data. The next layer of that intelligence foundation is more specific and far more overlooked. It is not more data that banks need. It is better-labelled data. Because in business banking, raw data alone does not create intelligence. Annotated data does.
The Illusion of “More Data = Less Risk”
The rise of digital data fundamentally changed how lenders assessed SME and commercial borrowers. With access to bank statements, tax filings, transaction feeds, and an expanding range of alternative signals, the prevailing logic was straightforward: more information would mean fewer surprises, and fewer surprises would mean lower risk. Except it did not hold.
A business with volatile cash flows remains risky regardless of how much data exists about it. What additional data actually improves is narrower and more specific: the institution’s ability to differentiate. That means identifying stronger borrowers with greater confidence, detecting weaker ones before deterioration sets in, and pricing with more certainty. Data improves visibility. It does not automatically create judgement.
The same misconception is now possibly repeating in AI. Across banking, significant investment is being directed toward models, infrastructure, and automation. Documents are digitised, statements parsed, and AI systems can summarise large volumes of information in seconds. And yet a familiar ceiling is already visible. AI systems can extract and process information at scale. What they often cannot do is interpret it in ways that align with institutional judgement, policy frameworks, or contextual business understanding.
A transaction can be extracted. But is it operational, exceptional, or a signal of deteriorating cash management? Revenue can be identified. But is it recurring, concentrated, or in structural decline? These are not technical questions. They are judgement questions — and this is where many AI initiatives in business banking are beginning to stall, not because the models are insufficient, but because the data feeding them has not been structured to carry meaning.
Key Takeaway
Data improves visibility. It does not automatically create judgement. Without annotation, AI remains an extraction engine not a decision partner.

The Intelligence Foundation: raw data creates visibility; annotated data creates intelligence.
The Real Differentiator Is Already Inside the Institution
AI discourse in banking still focuses too heavily on models and public data. Yet the most valuable data is internal: transaction histories, behavioural signals, customer interactions, credit decisions, and portfolio outcomes accumulated over time. This data does more than store information. It reflects how a bank understands customers, assesses risk, and makes decisions.
The judgement of experienced Relationship Managers, the outcomes of approved and declined applications, and the rationale in credit memos together form concentrated institutional intelligence. Without structure and annotation, it stays trapped in people and legacy systems instead of strengthening AI capability.
Frontier models are becoming broadly accessible. The intelligence layer built on top of proprietary, annotated data will not be. In a world where model capability is increasingly commoditised, the real competitive advantage lies not in which model an institution deploys but in whether that institution has systematically contextualised, annotated, and operationalised its proprietary data. That transformation is what turns patterns into intelligence, and institutional judgement into repeatable, scalable systems.
Key Takeaway
In a world where frontier models are commoditised, well-annotated proprietary data becomes the real differentiator. Models may become widely accessible. Institutional intelligence will not.

The Only Sustainable Edge: in a world where models are increasingly commoditised, well-annotated proprietary data becomes the only sustainable competitive advantage.
From Tagging to Institutional Intelligence
AI does not become useful in business banking simply because more information becomes available. It becomes useful when information progressively acquires structure, context, meaning, and decision relevance. That evolution moves across multiple layers. Tagging and labelling assign initial structure. Chunking separates content into decision-relevant units. Semantic layering adds contextual meaning, connecting a transaction pattern to a risk indicator or a contract clause to a concentration risk. Annotation links information to institutional policy and decision logic. At the highest layer, ontology maps the full vocabulary of how the institution understands its borrowers, sectors, and risk signals.
Together, these layers transform raw transaction data into institutional intelligence. The objective shifts from processing information to enabling AI systems to interpret business context, customer behaviour, policy alignment, and decision relevance in a manner that reflects how the institution actually reasons.
Key Takeaway
The most important question in business banking is rarely ‘what does the data say?’ It is ‘what does this information mean for a decision?’ Annotation is the mechanism that bridges those two questions.
From Tagging to Annotation: each layer adds more meaning. Together, they turn data into institutional intelligence.
Teaching Models How the Institution Thinks
One of the more persistent misconceptions in enterprise AI is that better automation produces better decisions. In business banking, this is not guaranteed. AI systems can extract fields, categorise transactions, and identify patterns at scale. But financial data is nuanced, and models left without institutional grounding frequently misinterpret edge cases, lose context, and produce outputs that do not reflect how experienced practitioners would reason about the same information.
The institutions that build durable AI capabilities will not be those that remove human expertise from the process. They will be the ones that systematically capture and feed institutional judgement back into their systems. This is the deeper significance of approaches such as Reinforcement Learning with Human Feedback (RLHF). The development is not simply that models learn. It is that institutions can begin teaching models how they think: how risk is interpreted, how policy is applied, how exceptions are reasoned through. Over time, this feedback loop does more than improve output accuracy. It transforms institutional expertise into scalable intelligence.
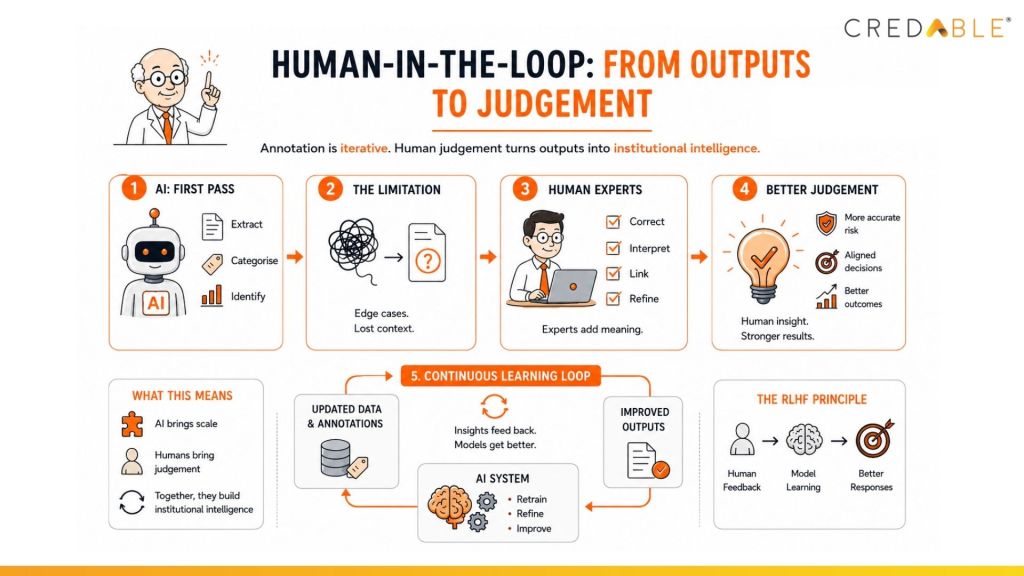
Human-in-the-Loop: annotation is iterative. Human judgement turns AI outputs into institutional intelligence through a continuous learning loop.
Practitioner Note
The development is not simply that models learn it is that institutions can begin teaching models how they think: how risk is interpreted, how policy is applied, how exceptions are reasoned through.
A useful analogy is already familiar to every credit practitioner: the difference between a bureau score and an internal credit scorecard. Bureau scores are powerful because they are trained across millions of borrowers at scale, providing broad, standardised intelligence and a credible baseline for risk assessment. But competitive lending decisions are rarely made on bureau scores alone. The advantage comes from layering proprietary intelligence on top: portfolio behaviour, transaction patterns, internal risk appetite, and historical repayment outcomes. That is what custom scorecards do.
The same principle now applies to AI systems. Frontier models provide broad reasoning capability, much as bureau scores provide broad credit intelligence. Institutional differentiation will come from fine-tuned systems, Small Language Models, context engineering, and Retrieval-Augmented Generation (RAG) architectures: all built on top of annotated proprietary data. The frontier model provides the base intelligence. The proprietary AI layer provides the institutional judgement.
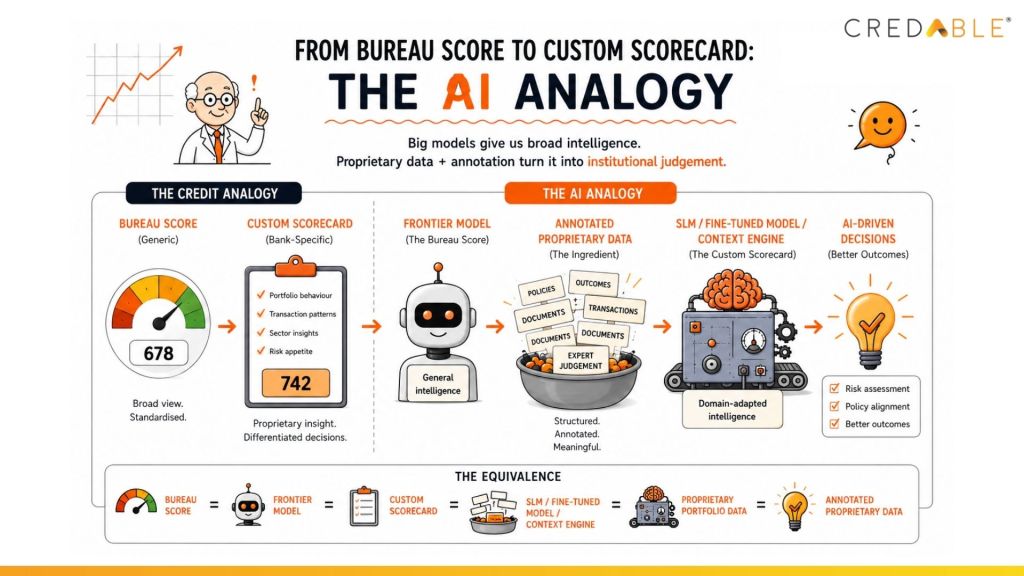
The AI Analogy: frontier models give broad intelligence, just as bureau scores give broad credit intelligence. Institutional differentiation comes from the proprietary layer built on top.
The Annotation Playbook
Operationalising annotation consistently is the challenge most institutions face. The concept is rarely disputed. The execution is. In practice, annotation evolves into an institutional capability built around four principles: defining a shared business and risk ontology; structuring unstructured data into decision-relevant units; layering annotation from structural to semantic to decision intelligence; and continuously refining systems through human feedback. What begins as data structuring becomes something more durable — a system for capturing how the institution reasons.
A transaction dataset may initially be tagged and categorised. Through annotation, it can then be interpreted to identify recurring supplier payments, customer concentration, and cash flow volatility, each mapped to risk indicators and policy thresholds. What begins as data processing gradually becomes institutional intelligence.
In regulated industries, this layer serves an additional purpose. Annotation creates a verifiable record of how decisions are formed. Each layer improves traceability, explainability, accountability, and governance. Without it, AI systems may generate outputs but cannot reliably justify them to regulators, auditors, or the borrowers whose applications they inform.
Annotation also changes the economics of AI deployment. Structured, contextually-labelled data reduces prompt length, improves retrieval precision, lowers token consumption, reduces hallucination rates, and makes human intervention more targeted. Annotation reduces decision cost, not just model cost.
Banking Implication
The biggest mistake banks can make is assuming the model will figure out context on its own. It will not. Without annotation, AI systems may generate outputs but they cannot reliably justify them.
The Investment That Will Actually Differentiate
The institutions directing investment toward model selection and vendor ecosystems are making decisions that matter. But they will not differentiate on this basis alone. As AI adoption accelerates, most institutions remain focused on infrastructure, tooling, and deployment. These are necessary investments. They are not sufficient ones.
Proprietary data creates the potential for differentiation. Annotation determines whether that potential is realised. If the last decade in business banking was about digitising data, the next decade will be about teaching systems how institutions interpret it. Data improves visibility. Annotation enables understanding. Without it, AI remains largely an efficiency tool. With it, AI begins to operate in the language that matters most in business banking: judgement, consistency, accountability, and trust.
Key Takeaway
Proprietary data creates the potential for differentiation. Annotation determines whether that potential is realised. Without it, AI remains largely an efficiency tool.
Three Priorities to Act On Now
Establish a shared business and risk ontology before scaling any AI initiative. Structure: Build annotation frameworks that connect information to institutional policy and decision logic. Govern: Treat annotated, proprietary data as a core competitive asset, not a data management exercise.
This article is part of the “Re-Architecting Business Banking with AI” series, this article explores why data annotation is becoming a foundational investment for AI-first business banking. Read the Article
About the Author: Satyam Agrawal is an experienced professional at the intersection of Banking, FinTech, and Digital Platforms, with a focus on AI-enabled transformation of business banking. His work spans SME Banking innovation, Digital Value Proposition, and Analytics. He currently works at CredAble, helping bridge the gap between traditional finance and next-generation intelligence systems.
The views expressed are solely his own and do not represent the views of any organisation. Follow him on LinkedIn: https://www.linkedin.com/in/satyamhere/
People Also Ask -
Data annotation in banking is the process of labelling and contextualising financial data so AI systems can interpret transactions, documents, borrower behaviour, credit signals, and policy logic more accurately.
It helps AI systems move beyond extraction and summarisation by adding business context, decision relevance, risk meaning, and explainability.
Annotated data helps lenders identify recurring revenue, cash flow volatility, customer concentration, repayment behaviour, and early warning signals with greater consistency.
Raw data shows what happened. Annotated data explains what it means for a business decision.
It creates a clearer trail of how information is interpreted, how decisions are formed, and how AI outputs align with internal policy and regulatory expectations.
Think Working Capital… Think CredAble!