Re-architecting Business Banking with AI: How AI, data and digital infrastructure will reshape business banking.

AI in banking is no longer limited to automation or cost efficiency anymore. The next phase will be defined by how banks interpret unstructured data to make better credit and risk decisions.
For AI to fundamentally transform business banking, the catalyst will not be the deployment of superior models, aesthetically pleasing dashboards, or generating routine memos. Instead, it will necessitate institutions mastering the comprehension of unstructured data, which has been largely overlooked.
Today unstructured data represents a staggering 80% of all new enterprise data, growing at 3x the pace of structured data.
But only 18-25% of banks effectively leverage unstructured data or are prepared for AI scaling, with most stuck in pilots due to data infrastructure limitations.

How a bank addresses this data will determine whether AI remains an efficiency tool or evolves into a revolutionary decision-making capability.
Within the context of Business Banking, most of the critical business and risk intelligence resides outside core systems, where majority of data is either Unstructured (e.g., call notes, internal policies, credit assessment memos) or, at best, Semi-Structured (e.g., Financial Statements, Bank Statements).
While this raw unstructured data historically presented challenges in terms of inefficiency and risk, the advent of AI now offers a substantive opportunity to transform this material into a robust layer of business and credit intelligence that can serve as a significant competitive advantage. Structured data elucidates ‘what’; unstructured data provides the explanation for ‘why’. The most compelling value of unstructured data, particularly the Proprietary Data Corpus, lies in its capacity to hold the institution's unique business and risk philosophy, capturing the accumulated expertise of experienced Relationship Managers and Analysts over time.
Consider a bank that has developed deep domain knowledge in Business Lending, accrued through years of experience spanning multiple credit cycles; this "Credit Judgment DNA" becomes irreplicable for competitors, even if they utilize comparable or better AI models. Unstructured Data contains the tacit knowledge that captures the qualitative rationale behind underlying decisions, such as the justification for approving a borrower despite a deviation from standard financial ratios
The Reality of Data in Business Banking
Business banking operations rely on a combination of financial, operational, legal, and human-centric information concerning Small and Medium-sized Enterprises (SMEs).
The reality is that most of this data was originally created for human interpretation, not for computational models.
A foundational understanding of data types is essential for generating actionable intelligence. In this context, data can be classified into the following categories:
| Data Type | Characteristics | Examples |
| 1. Structured Data | Sparse, highly condensed, captures outcomes without context. Reliable but incomplete. Tells what, rarely why. | Firmographics, financial ratios, credit scores, external debt, etc. |
| 2. Semi-Structured Data | Richer but fragile, sits between tables and free text. Highly dependent on format consistency. | Bank statements, tax filings, payroll records, audited financials, etc. |
| 3. Unstructured Data | Repository of true understanding, created for human communication. Where intent, nuance, causality, and professional judgment reside. The context layer. | Loan proposals, contracts, emails, relationship manager notes, call transcripts. |
Unstructured data is not all the same, and includes:
● Publicly (Open Source) available → Websites, Regulatory Filings, news articles, court records. Valuable for training baseline models.
● Federated (Shared/Anonymized) → Data shared via Networks or Banking Consortiums (e.g., Quarterly Bureau Reports). Useful for cross-institutional patterns.
● Proprietary (Competitive Moat) → Generated within the bank–SME relationship, captures institutional DNA. Includes RM notes, credit memoranda, internal policy documents.
From ‘Large Language Model’ to a proprietary ‘Lending Language Model’

Historically, unstructured data was difficult to standardize and did not align with existing modeling paradigms.
However, with Large Language Models (LLMs) and their capability to process vast volumes of text via vector embeddings, unstructured data offers significant leverage, leading to enhanced context, which in turn leads to superior intelligence.
Consider the potential of AI-Assisted Credit Decisioning, which can generate a Credit Assessment Memorandum from raw inputs such as financials, bank statements, and other application documents. While this offers efficiency, generating a well-formatted memo with a summary and credit recommendation based on billions of trained parameters, it inherently lacks the bank's specific risk appetite and proprietary experience.
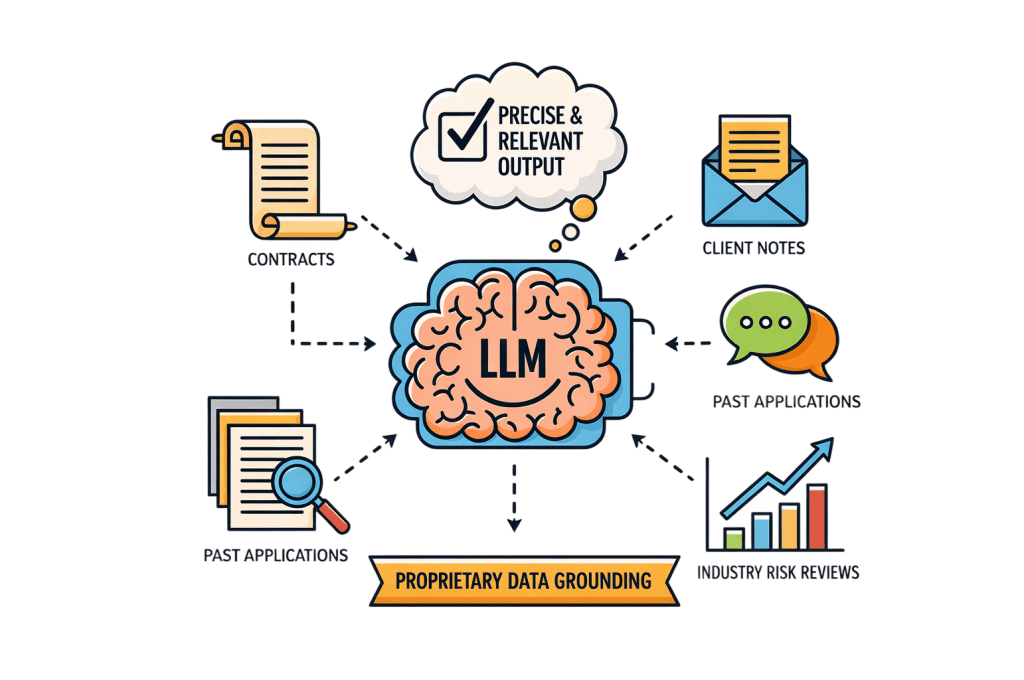
To ensure the results are pertinent and precise, one must consider grounding the same Large Language Model (LLM) with crucial, proprietary unstructured data prior to generating the final output. This data would encompass contracts, emails, client notes, past analogous applications assessed by the lender, and relevant industry or sector risk reviews.
By integrating this deep, proprietary context, a significant improvement in the outcome will be realized. This outcome is primarily achieved either by grounding an LLM or by potentially developing a proprietary small or domain-focused model.
When done right, i.e. unstructured data is truly operationalized, decisions become context-aware rather than strictly rule-bound. Credit assessments are enhanced and become more readily explainable. Early warning signals are surfaced earlier. Exceptions are rationalized rather than being treated as ad hoc occurrences. Relationship managers can devote less time to summarization and more time to critical judgment. Trust is augmented internally, with regulators, and externally with SMEs.
The benefit extends beyond mere speed or cost reduction, culminating in superior decisions delivered at scale.
Conversely, mishandling this data, such as feeding raw text directly into models without proper schema and labels, or over-trusting probabilistic outputs without comprehending the underlying reasoning paths, may cause substantial financial and reputational harm besides embarrassment. The biggest mistake banks can make is assuming the model will figure it out on its own. It won’t.
Operationalizing Unstructured Data: A Strategic Imperative

Large Language Models do not possess an innate understanding of the raw content of documents. Transforming unstructured data into usable business intelligence necessitates a deliberate, three-stage methodology: extraction, normalization, and annotation.
This sequence is mandatory. Without it, AI systems remain "probabilistic guessers" rather than reliable "decision partners."
- Extraction converts text, documents, and audio into machine-readable formats.
- Normalization standardises disparate formats into comparable, consistent conceptual frameworks.
- Annotation (in conjunction with schemas) provides the essential context that connects facts to underlying causes and facilitates logical reasoning across various signals and over time.
The current reality is that crucial business data (PDFs, emails, and site visit reports) remains siloed outside core processing engines, confining most AI initiatives to marginal 'pilots.'
In the next 12–24 months, Banks that decisively move to construct proprietary data corpora will have capitalized on the opportunity to transition beyond mere efficiency tools to achieve a breakthrough in decision-making.
To secure this distinct competitive advantage, banks must make three immediate, strategic investments:
- Build: Invest and expand the unstructured data corpus.
- Structure: Prioritize developing robust annotation frameworks and schemas.
- Asset-Focus: Treat this annotated, unstructured data, which captures institutional memory, as a core, proprietary competitive asset.
This article is part of the series : “Re-Architecting Business Banking with AI,” which explores how data architecture, decision science, and AI-first operating models will reshape the future of business banking.
About the Author: Satyam Agrawal is an experienced professional at the intersection of Banking, FinTech, and Digital Platforms, with a focus on AI-enabled transformation of business banking. His work spans SME Banking innovation, Digital Value Proposition, and Analytics. He currently works at CredAble, helping bridge the gap between traditional finance and next-generation intelligence systems.
The views expressed are solely his own and do not represent the views of any organisation. Follow him on LinkedIn: https://www.linkedin.com/in/satyamhere/
Think Working Capital… Think CredAble!